Debido a la naturaleza del entorno de ejecución de los smart contracts, en los que se maneja dinero, existe un incentivo para que existan usuarios maliciosos para los que exploten las debilidades de implementación y obtengan lucro de dichas debilidades.
Consideremos el escenario, donde la blockchain se encuentra en un estado 
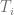
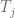

![\Delta[\alpha]](https://s0.wp.com/latex.php?latex=%5CDelta%5B%5Calpha%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
![\Delta'[\alpha]](https://s0.wp.com/latex.php?latex=%5CDelta%27%5B%5Calpha%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
TOD tiene puede ser utilizado para realizar ataques al estado de la blockchain de modo que se puedan obtener beneficios del modo en que se ejecutan estas transacciones.
Observemos el siguiente smart-contract que representa una tienda que vende un producto:
contract MarketPlace {
uint public price;
uint public stock;
/.../
function updatePrice(uint _price) {
if (msg.sender == owner) price = _price;
}
function buy(uint quant) returns (uint) {
if (quant > stock || msg.value < quant * price) throw;
stock -= quant;
/.../
}
}
A partir del código anterior, supongamos la siguiente ejecución dentro de la blockchain:
y
son transacciones que son invocadas de forma simultanea y son obtenidas por el mismo minero.
- El minero mina el bloque que contiene a
- Se escribe el estado de la ejecución de las transacciones dentro del bloque y se actualiza el estado
En esta ejecución todo funcionó de forma esperada sin que fallara nada. Pero que pasa si consideramos la siguiente ejecución:
- El minero mina el bloque que contiene a
- Se escribe el estado de la ejecución de las transacciones dentro del bloque y se actualiza el estado
En este caso el cliente compró el producto a un precio más caro que el que él esperaba. Esto se traduce en que el dueño se benefició de la forma en que la transacción se ejecutó, aunque esto no fue de forma consiente. ¿Qué pasaría si nos aprovechamos de esta falla?
Veamos un caso más en el que el orden de la ejecución de los contratos puede causar un estado imprevisto en la ejecución bajo TOD. Sea el siguiente código:
contract Puzzle {
address public owner;
bool public locked;
uint public reward;
byte32 public diff;
bytes public solution;
function Puzzle() {
owner = msg.sender;
reward = msg.value;
locked = false;
diff = bytes(111111);
}
function () {
if (msg.sender == owner) {
if (locked) throw;
owner.send(reward);
reward = msg.value;
} else {
if (msg.data.length > 0) {
if (locked) throw;
if (sha256(msg.data) < diff) {
msg.sender.send(reward);
solution = msg.data;
locked = true;
}
}
}
}
}
El contrato anterior recompensa a los usuarios quienes resuelven un acertijo computacional. Sólo si el hash del mensaje enviado por el jugador es menor que una diferencia predefinida, entonces, se paga la recompensa al jugador y se bloquea el contrato para que nadie más intente jugar después.
Igualmente consideremos dos ejecuciones de el contrato Puzzle en una blockchain. La primera ejecución la podemos describir de la siguiente forma:
- El minero mina el bloque que contiene a
- Se escribe el estado de la ejecución de las transacciones dentro del bloque se actualiza el estado
En este caso el jugador esperaba recibir la recompensa que el observó cuando envió su solución, pero el recibió una recompensa distinta, el cuál pudo haber sido un accidente, pero ¿y si no fue un accidente?
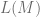 un lenguaje y
un lenguaje y 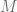 una máquina de Turing.
una máquina de Turing.  Por hipótesis
Por hipótesis  Supongamos que existe una máquina de Turing no determinista
Supongamos que existe una máquina de Turing no determinista  que decide
que decide  , todas las ramas de ejecución de
, todas las ramas de ejecución de  es decidible
es decidible  MT M no-determinista que lo decide.
MT M no-determinista que lo decide. 