En estos días, me he sentido muy «improductivo», debido a que he tenido muchas distracciones y siento que me estoy atorando en varias tareas.
Antes de retomar esas tareas, he considerado necesario el buscar alguna(s) técnica(s) que me permita recuperar mi productividad en base a pequeños ajustes.
Una de las técnicas que voy a comenzar a probar es la técnica pomodoro, desarrollada por Francisco Cirillo a finales de 1980. La idea de esta técnica es dividir tu tiempo en intervalos de 25 minutos (llamados pomodoros) separados por pequeñas pausas de 5 minutos y después de 4 pomodoros, tomar una larga pausa de 15-30 minutos.
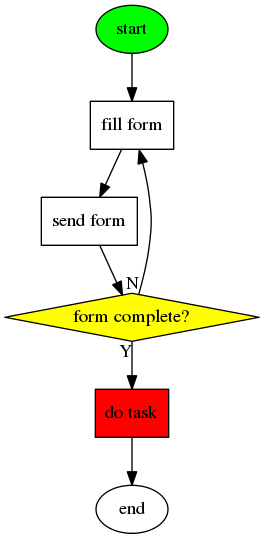
Para aplicar esta técnica es necesario en cuenta las siguientes etapas:
- Planeamiento
- Anotación
- Registro
- Proceso
- Visualización
En la etapa de planeamiento, se listan todas las tareas que se tienen que hacer «para hoy», lo cuál permite a los usuarios estimar los esfuerzos que cada tarea puede requerir. En la etapa de anotación se incia la tarea a enfocarse, dedicando los pomodoros necesarios para realizarla.
Cada vez que se termina un pomodoro, hay que registrar el fin del pomodoro con una etiqueta indicando que se terminó el pomodoro. Generalmente esto se realiza mediante una X.
Y en la etapa de visualización, se hace un análisis estadístico acerca de las actividades realizadas para determinar el tiempo aplicado.
Para hacer lo anterior, lo recomendado es realizar los siguientes cinco pasos:
- Decidir la tarea a realizar
- Poner el pomodoro a ejecutar (25 minutos)
- Trabajar en la tarea hasta que el pomodoro termine y anotar una X en la lista de tareas
- Tomar una pausa breve (5 minutos)
- Cada cuatro «pomodoros», tomar una pausa más larga (15-30 minutos).
Un objetivo esencial de esta técnica es eliminar las interrupciones, tanto internas como externas. Esto se hace registrándolas y posponiéndolas siempre que sea posible. En caso de que la interrupción sea crítica, se debe resolver la interrupción y reiniciar el trabajo con los pomodoros.



 |
| 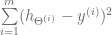
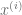 = entrada de características del
= entrada de características del  ejemplo de entrenamiento
ejemplo de entrenamiento
 = valor de la característica j en el
= valor de la característica j en el 
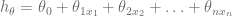
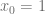

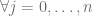 )
)
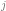
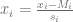 , donde
, donde  es el valor promedio para x
es el valor promedio para x en el conjunto de datos, y s
en el conjunto de datos, y s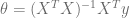
 = pinv(X’ * X) * X’ * y
= pinv(X’ * X) * X’ * y
 [ Today’s exercise comes from the
[ Today’s exercise comes from the 